

.png?width=207&height=108&name=Mega%20menu%20%E2%80%93%20Featured%20Image%20Template%20(1).png)
 UK
UK
 France
France
 Germany
Germany
 Italy
Italy
 Spain
Spain
 Poland
Poland
.svg) Australia
Australia
 Japan
Japan
 USA
USA
 Canada
Canada



In this blog series, we're proud to shine a light on some of the top Capstone projects from the first graduating class of Data Science for All / Empowerment. Capstone projects are a critical component of the DS4A / Empowerment curriculum in which teams get together to work on projects that solve real-world data challenges faced by today’s leading companies and public sector organizations.
Meet the Team
 Marie-Claire Traore
Marie-Claire Traore
Education: B.S. in Information Technology, Colorado State University
“I chose to join DS4A / Empowerment for the opportunity to develop an impactful project in a highly collaborative and supportive environment. I wanted to learn how to use data science to create solutions for social good. After the program, my goal is to specialize in machine learning as a software engineer by furthering my studies in computer science. I would also like to research ethics in AI to promote equitable and inclusive AI practices.”
 Sathya Edamadaka
Sathya Edamadaka
Education: B.S. Candidate in Electrical Engineering and B.S. Candidate in Physics at Stanford University, ‘23.
“I chose to join DS4A / Empowerment at first because I wanted to learn about data science. I later realized the enormous impact our work could have, and thought there was no better way to try to apply what I knew. After the program, my goal is to continue to pursue high-impact projects in data, specifically in the realm of energy production devices through polymer and computational physics, experimental synthesis of data-backed solar cell designs, and beyond.”
 Will Walker
Will Walker
Education: B.S. Candidate in Data Science, Concentration in Computational Analytics, Minor in Cognitive Neuroscience, Temple University, ‘23.
“I chose to join DS4A because I wanted to gain education, experience, and exposure in data science; learning how to think about complex problems that governments face in service to their citizens. After the program my goal is to pursue studying implementation realities of public policy addressing climate solutions, particularly as pertains to transportation, housing, and infrastructure.”

Kristen Ray
Education: BA Cognitive Science SUNY Oswego, MA Human Computer Interaction SUNY Oswego
“I chose to join DS4A / Empowerment because I believe in the vision. Working as a consultant, I see the impact data can have on policy and people, and the importance of having someone in the room to advocate for the perspectives of vulnerable communities.After the program my goal is to integrate what I learned to my work and take advantage of opportunities to work directly with datasets. To promote equity in policy creation.”
About the Project: When the Levees Broke
Why did you choose this problem to solve?
We chose our problem to help support the management and design of coastal infrastructure to minimize damage caused by tropical storms. The feature importances of our model would guide cities as to which aspects of their infrastructure, weather, or development are most dangerous within the context of exacerbating the impact of these natural disasters, guiding future investment and planning.Project Overview
Project Highlights
.png?width=1424&name=Modeling%20Pipeline_Team%2017%20(1).png)
Figure 1. The sources of data, general modeling pipeline, and outputs (the EDA graph and predictive graphs below)
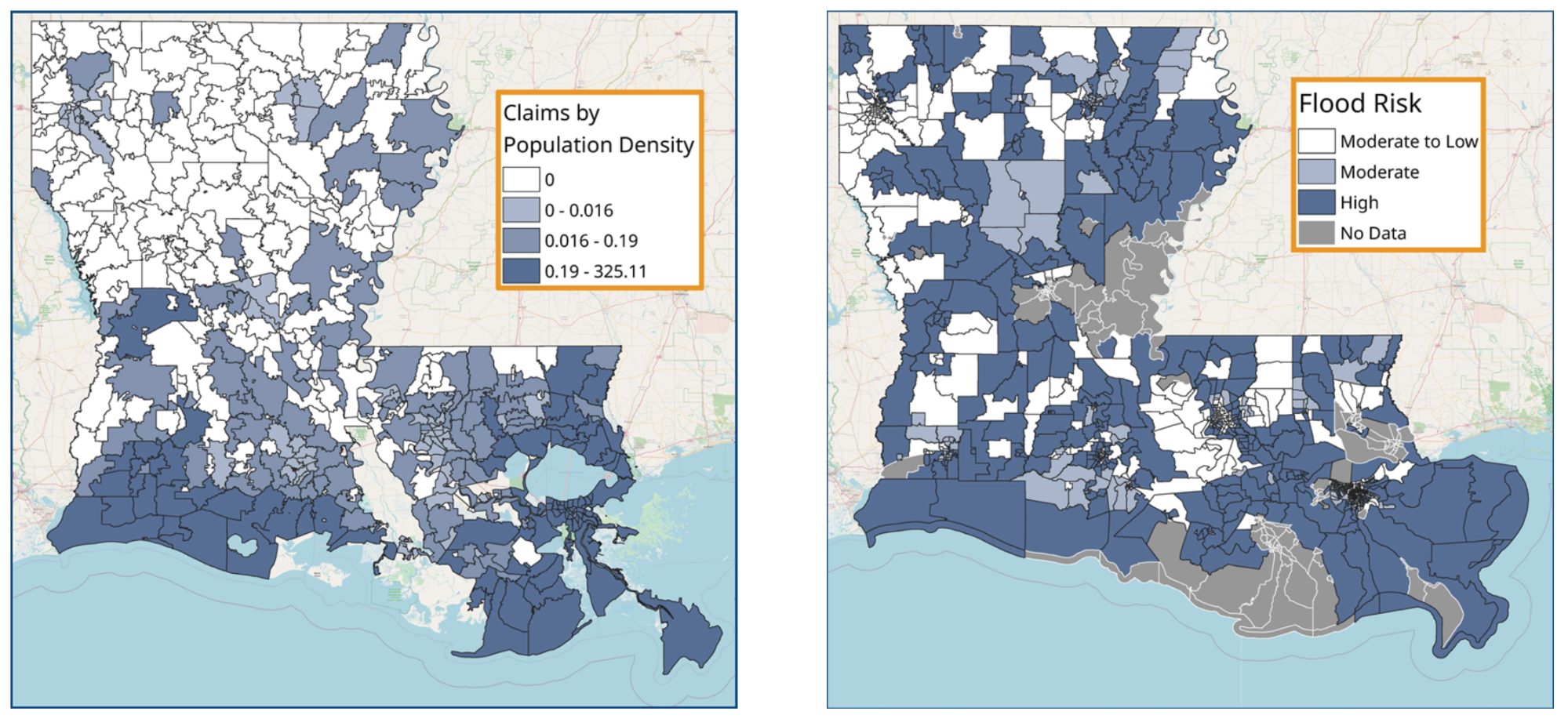
Figure 2. Visualizations of EDA; namely, how many people reported flood damages after Katrina in contrast to the geographical risk of each zip code
.png?width=1999&name=Model%20Accuracies%20(XGBoost%20and%20Artificial%20Neural%20Network).png)
Figure 3. The main results! These show visualizations for the accuracies of the models, as well as the major differences in the features each thought was important.
For more details, click here to see the dashboard on Data Studio, and click here to see the analysis on GitHub.
What were some challenges you faced, and how did you overcome them?
Size of the Dataset
We were primarily focused on one state during the recovery period of one storm. For the sake of time and complexity, we remedied this issue by oversampling using the BorderlineSMOTE method.
Normalizing the Data
Since each zip code has a different area and population size, we decided to normalize the insurance claims data from each zip code by population density.
Type of Target Data
We had to shift our approach, turning our regression problem into a classification problem.
The Challenge of Model Building
We started off using a number of models, both simple and complex, eventually settling on two that gave us accurate, but not overfitted, results.
What was the most exciting/surprising finding from your project?
We hoped our novel addition to flood risk prediction would be the inclusion of socioeconomic data. Upon completing our XGBoost and Artificial Neural Network models, we were astounded to see exactly that. Our more sensitive model that picked up on areas like the Lower Ninth Ward, which have historically been underfunded because of systemic racism and injustice, heavily used socioeconomic data in making its risk assessments.
Who is your team’s mentor and how did they help?
Our mentors for the project were Chuck Ni, Manager of Statistical Programming at Gilead and Raul Aguilar, Associate Director of Biostatistics at Gilead. Chuck and Raul’s expertise were integral to the completion of our project. They provided advice and feedback through every stage of our project from idea formation to the development of our statistical analysis and modeling. Their advice helped us to overcome hurdles and refine our approach to create an impactful solution to our research question.
What do you view as the impact of your project?
We hope our findings can possibly have a significant impact on the future infrastructure considerations of the state of Louisiana; improving the quality of life and safety of those living in flood zones, leading to more meaningful, effective, and equitable climate mitigation efforts in the state.
We believe doing more research to discover insights regarding risk and race, gender, income, and education status would be hugely beneficial to state and local governments throughout the Southeast - and beyond - to generate better risk assessments, build better infrastructure, and optimize disaster response.